Architecture
A schematic diagram of Genero Report Writer for Php

Scalability
A schematic diagram illustrating the distributed nature of Genero Report Writer for Php

A schematic diagram of Genero Report Writer for Php
A schematic diagram illustrating the distributed nature of Genero Report Writer for Php
Detailed feature overview
Customizing the presentation
Data production and presentation separated
Structured data source
Performance & scalability
Sophisticated layout engine
APIs
Report viewers and devices
Run time localization
Templates
Maintenance
Data source generation
Database support
All of the industry’s leading databases are supported:
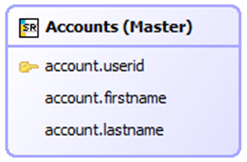
Create data model from the database
In this example we use the dataset designer to define the data object for the report
Generate schema and PHP code
Building the data model in the project manager creates the XML schema and the PHP code.
Graphical reports are designed based on a XML schema that matches the data to be serialized.
The schema file Accounts.xsd for the sample program reads as follows:
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified">
<xs:element name="Accounts">
<xs:complexType>
<xs:sequence>
<xs:element name="Accounts" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="account_userid" type="xs:string"></xs:element>
<xs:element name="account_firstname" type="xs:string"></xs:element>
<xs:element name="account_lastname" type="xs:string"></xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>The PHP code for the sample program reads as follows:
Accounts_main.php
set_include_path(get_include_path().PATH_SEPARATOR.getenv("PHPINCLUDEDIR"));
require_once 'Accounts_lib.php';
require_once 'libgrerunners.php';
$dsn='sqlite:officestore.db';
$pdo = new PDO($dsn, '', '');
$pdo->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC);
if ($argc == 1) {
$designFile = 'Accounts.4rp';
} else {
$designFile = getcwd().DIRECTORY_SEPARATOR.$argv[1];
}
$greRunnerObj = new GreRunner($designFile, 'Accounts');
$greRunnerObj->selectDevice('PDF');
$greRunnerObj->selectPreview(true);
$greRunnerObj->configureDistributedProcessing("127.0.0.1",7000);
try {
$greRunnerObj->run(new Accounts($pdo));
} catch (UserAbortException $e) {
} catch (GreRuntimeException $e) {
echo "GreRuntimeException: ".$e->getMessage()."n";
} catch (Exception $e) {
echo "Exception: ".$e->getMessage()."n";
}
Accounts.php :
require_once 'libgretypes.php';
require_once 'libgrerunners.php';
class Accounts extends SerializableRecord
{
public $account_userid;
public $account_firstname;
public $account_lastname;
private $pdo;
private $query;
public function __construct($pdo)
{
$this->pdo = $pdo;
$this->query = '
SELECT account.userid as account_userid,
account.firstname as account_firstname,
account.lastname as account_lastname
FROM account
WHERE 1=1';
}
public function serialize(GreXMLConnector $greXmlConnector)
{
$stmt = $this->pdo->prepare($this->query);
$stmt->execute();
$row = $stmt->fetch();
while ($row !== false) {
$this->setValues($row);
parent::serialize($greXmlConnector);
$row = $stmt->fetch();
}
}
protected function serializeChildren(GreXMLConnector $greXmlConnector)
{
}
}
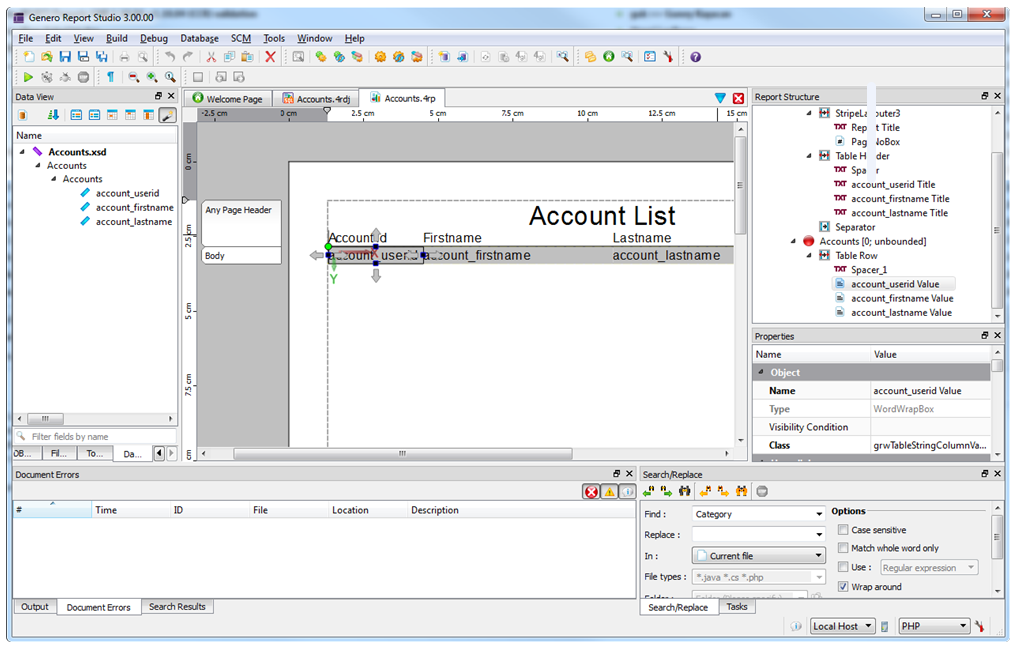
Design report from schema
Design the report using Report Designer. Choose your report template, associate the triggers and populate the report with data picked from the data view.
The image below shows “Accounts.4rp” created in the Report Designer:
Run report
The code to run the report was generated in Accounts_main.php. It selects the report design and configures the output.
Selecting the report design
if ($argc == 1) {
$designFile = 'Accounts.4rp';
} else {
$designFile = getcwd().DIRECTORY_SEPARATOR.$argv[1];
}
$greRunnerObj = new GreRunner($designFile, 'Accounts');
Configuring the output
Selecting PDF output
$greRunnerObj->selectDevice('PDF');
Serializing the model
Using PHP reflection to serialize the data.
parent::serialize($greXmlConnector);
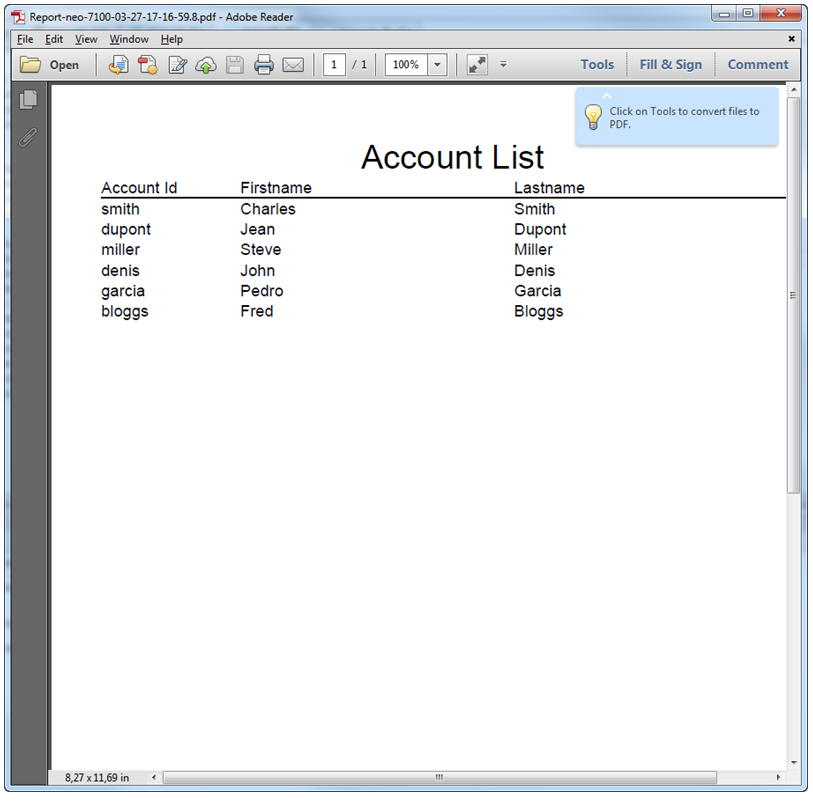
Resulting Report
Executing the above code produces the following PDF document: